

The complexity of distributed storage systems involves issues such as data disaster recovery, consistency, high-concurrency requests, and large-capacity storage. This article combines the evolutionary history of CnosDB in a distributed environment, sharing insights on applying distributed theory to practical production, as well as the advantages, disadvantages, and application scenarios of different implementation methods.
Distributed System Architecture Patterns
In distributed storage systems, based on different data replication methods, there are generally two modes: master-slave mode and leaderless mode.
Master-Slave Mode
Master-slave mode, represented by the Raft distributed algorithm, was introduced in the paper “In Search of an Understandable Consensus Algorithm” by Diego Ongaro and John Ousterhout in 2013. After its implementation in the etcd engineering case, the Raft algorithm gained significant popularity.
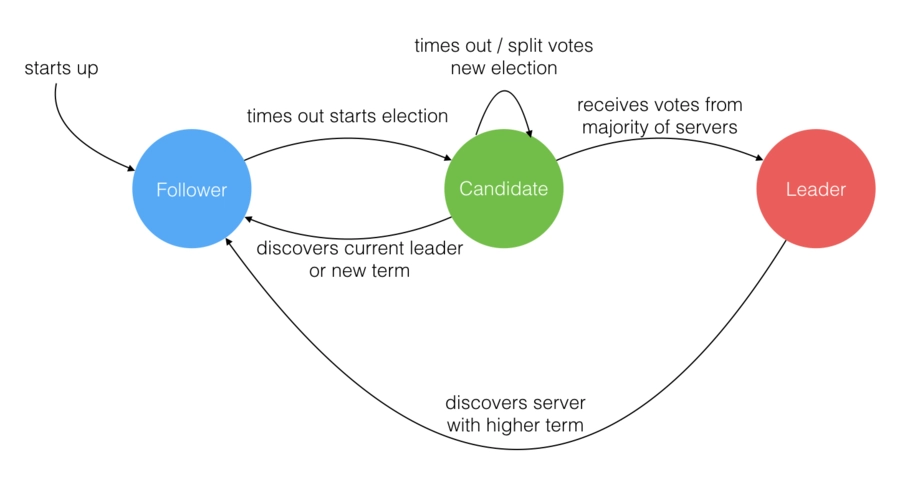
Leaderless Mode
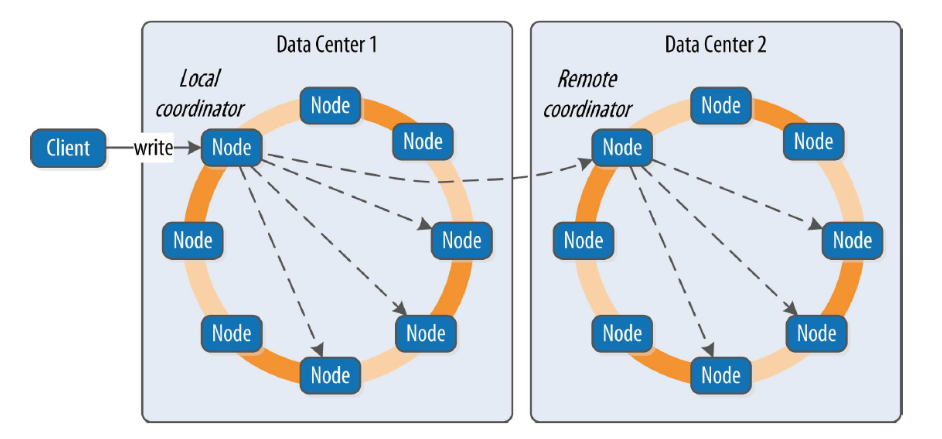
Leaderless mode, represented by Amazon's Dynamo model, is based on the theoretical framework presented in Amazon's 2007 paper “Dynamo: Amazon’s Highly Available Key-value Store.” This paper describes a leaderless database design, and systems like Cassandra and Riak are implementations based on this theory.
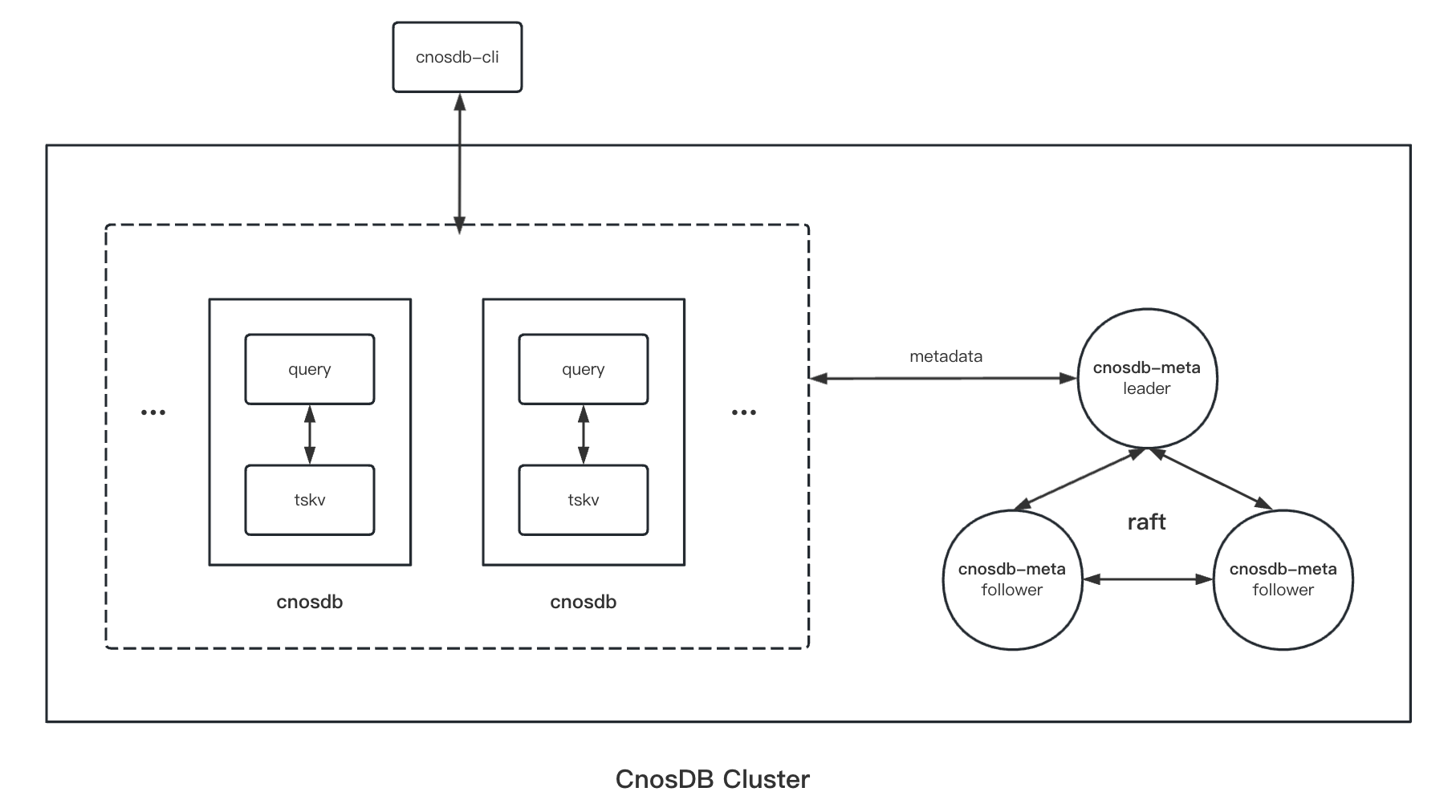
CnosDB Overall Architecture
The CnosDB architecture mainly includes two types of processes: cnosdb and cnosdb-meta. Cnosdb is responsible for data read, write, query, and storage, while cnosdb-meta handles metadata storage, including information about users, tenants, databases, tables, and data distribution.
CnosDB Service
CnosDB service is responsible for data write, read, and storage, functioning as a leaderless storage system similar to Dynamo.
CnosDB shards data based on two dimensions: time sharding and hash sharding.
Time Sharding: Due to the characteristics of time-series databases, sharding based on time has natural advantages. CnosDB creates a new bucket at regular intervals, with each bucket having a start and end time to store data for the corresponding time period. When the system capacity is insufficient, new storage nodes are added. When creating a new bucket, idle nodes with the most available capacity are prioritized, avoiding data movement and effectively addressing cluster expansion and data storage capacity issues.
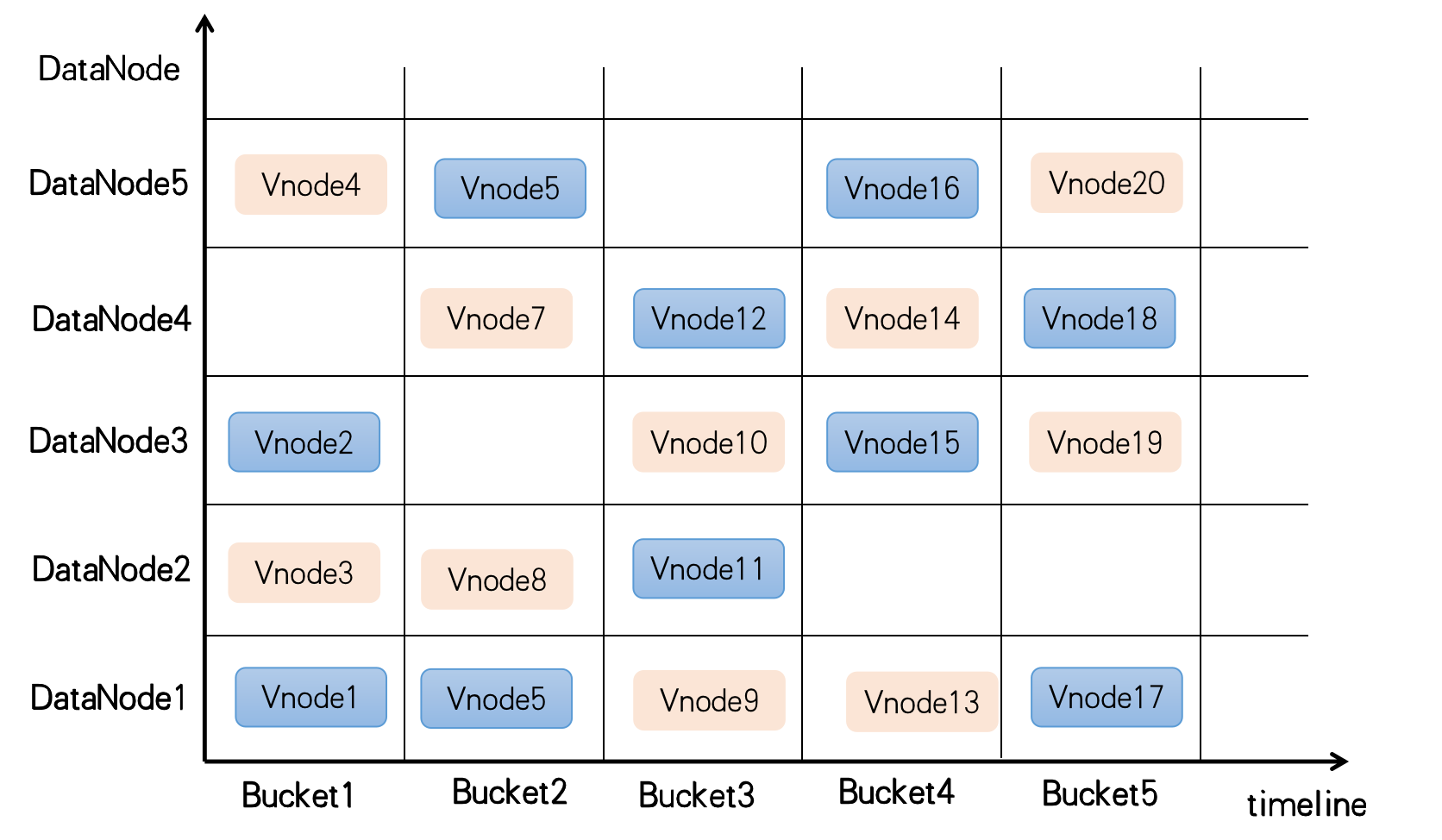
Hash Sharding: Time sharding addresses storage capacity issues, but in a distributed cluster, multiple machines provide services. If each bucket is distributed to a single machine node, the write performance of the entire system is limited to a single machine. Another concept in time-series databases is the SeriesKey. Hash sharding based on SeriesKey can split data into different ReplicaSets, each containing Vnodes (replica units). Each Vnode is scattered across different storage nodes, and multiple Vnodes in a ReplicaSet synchronize data between them in a Dynamo-like manner. Vnode is the basic unit for CnosDB's data sharding management, and hash sharding resolves system throughput issues.
The diagram below shows buckets created at regular intervals in the time dimension, each with two replica sets (different colors) distributed across different storage nodes.
Current Challenges
While sharding based on time and hash resolves capacity and performance issues in distributed storage, the leaderless mode introduces new challenges:
Data Consistency: Achieving data consistency in a leaderless distributed storage system has various approaches. Cassandra adopts a “last writer wins” approach, Riak uses vector clocks, and additional mechanisms like read repair, anti-entropy, and hinted handoff contribute to eventual consistency. Implementing these mechanisms is complex and can significantly impact system performance. CnosDB has implemented only a subset of these mechanisms.
Data Subscription and Synchronization: In a leaderless distributed storage system, data writes have no inherent order, making data subscription challenging. In leaderless mode, data writes uniformly enter the interface layer of the compute node. However, in a compute-storage-separated environment, the compute layer is often stateless, making data subscription challenging without the risk of data loss.
When Raft Meets CnosDB
To address these challenges, a transition to the master-slave mode was sought as a solution.
Semi-Synchronous Solution: Initially, a semi-synchronous solution inspired by Kafka was designed. Kafka controls the system's behavior in different modes through parameters, allowing users flexibility in choosing the desired consistency and reliability level. Considering the implementation difficulty, time constraints, and future stability, this solution was put on hold.
Other Solutions: The master-standby node approach was also discussed. However, due to CnosDB's multi-tenant nature, with different tenants or databases requiring varying numbers of replicas, some replica nodes may be underutilized, leading to uneven machine load and resource wastage.
Ultimately, the mature Raft solution, specifically the Multi-Raft approach, was chosen. In CnosDB, each ReplicaSet is a Raft replication group.
Why Choose Raft
Since the adoption of the Raft consensus algorithm in the etcd release, Raft has been recognized as a distributed consensus algorithm that is easy to understand and relatively easy to implement. It has been validated by numerous products for data consistency, stability, and reliability.
Raft operates in master mode, making it well-suited for achieving data consistency. Additionally, implementing data subscription is straightforward with Raft (e.g., as a learner node in the cluster or by directly reading Raft logs).
Furthermore, CnosDB's Meta service already uses Raft, providing another reason for embracing Raft in the main program.
There are also numerous open-source implementations of Raft in the community, making it a standard algorithm in current distributed systems. Therefore, there is no need to reinvent the wheel, and the openraft solution was chosen.
Application of Raft in CnosDB
In CnosDB, each ReplicaSet is a Raft replication group, and a ReplicaSet consists of multiple Vnode replicas distributed across different machines. These Vnodes form the member nodes of the Raft replication group.
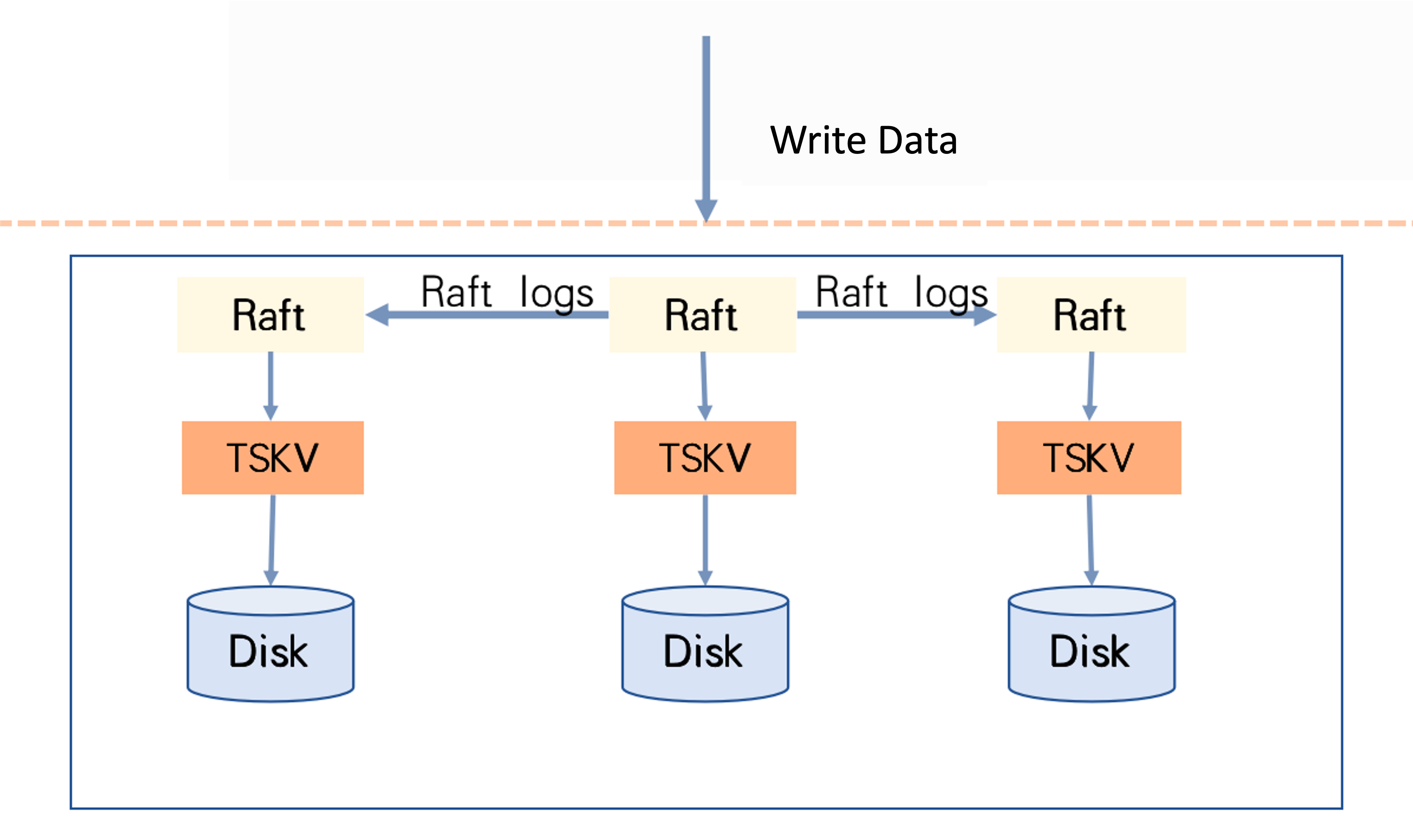
Data Write Process: In CnosDB, each write corresponds to a Raft replication group's commit. When the service receives a request, it checks whether the local node is the master node for the relevant Raft replication group. If not, it forwards the request. If yes, it performs the write using the Raft protocol, generating a Raft Log Entry for each Vnode node according to the Raft protocol. CnosDB records this in Write-Ahead Logging (WAL) format in the corresponding Vnode directory.
Once more than half of the Vnode nodes successfully record the WAL, the Raft protocol proceeds to the Apply phase. In CnosDB, the Apply phase is relatively simple; it involves writing to Memcache. After successful application by the master node, the client is notified of success.
After a service restart, data in Memcache is recovered through WAL. Memcache is flushed to disk under the guidance of the upper-level Raft protocol, and each Memcache flush serves as a snapshot.
For a more detailed process, refer to the Raft protocol documentation.
Data Read Process: Based on the query conditions, data reading ultimately reaches each Vnode. In CnosDB's plan, the master node's Vnode is prioritized for reading, ensuring higher data consistency. As CnosDB is a Multi-Raft implementation, master nodes are distributed across various nodes, avoiding uneven load distribution between master and slave nodes.
New Challenges
Raft consensus algorithm does not explicitly address the following scenarios:
Errors in reading/writing Raft logs Errors during Apply These two types of errors are typically IO errors, and encountering them puts the system in an unknown state. CnosDB attempts to minimize the occurrence of such errors through proactive pre-checks and refers to the approach used by etcd: if an unmanageable unknown scenario arises, manual intervention is required.
Enabling Raft Algorithm To enable the Raft algorithm, set the configuration item using_raft_replication to true in the configuration file.
using_raft_replication = trueCnosDB introduced the Raft consensus algorithm in version 2.4. While preserving high performance, availability, and ease of maintenance, this addition enhances data consistency in CnosDB queries. It also lays the groundwork for upcoming features such as data subscription, synchronization, and data heterogeneity processing.
As CnosDB's features mature, it will play a more significant role in a broader range of use cases. Future releases will include more test reports and usage scenarios for reference. Stay tuned for updates and growth together.